EN
企業的大部分文檔都是非結構化,不可編輯的,如何深度理解文檔結構,解析復雜文檔版面,將混亂的信息精準轉化為機器可讀的結構化數據呢?
根本原因在于,大多數傳統工具缺乏對文檔“版面結構”的深度理解。它們通常只停留在基礎的OCR(光學字符識別)層面,機械地將文字從頁面上“提取”出來,卻無法真正理解文字、圖片和表格之間的邏輯關系和閱讀順序。
但實際上,文檔的價值不僅在于文字本身,更在于其結構。無論是PDF、掃描件還是其他格式的文檔,其設計初衷都是為了方便人類視覺閱讀,通過字體、位置、間距等視覺元素來傳達標題層級、段落歸屬和表格關系。傳統工具無法解讀這種“視覺語言”,因此在解析時,常會將一個完整的表格拆得支離破碎,或者把不相關的文本塊錯誤地拼接在一起。
智能文檔解析系統(例如易道博識的產品)的核心優勢在于其高精度的版面分析,可以深度理解文檔的元素及邏輯結構,還原文檔版面。
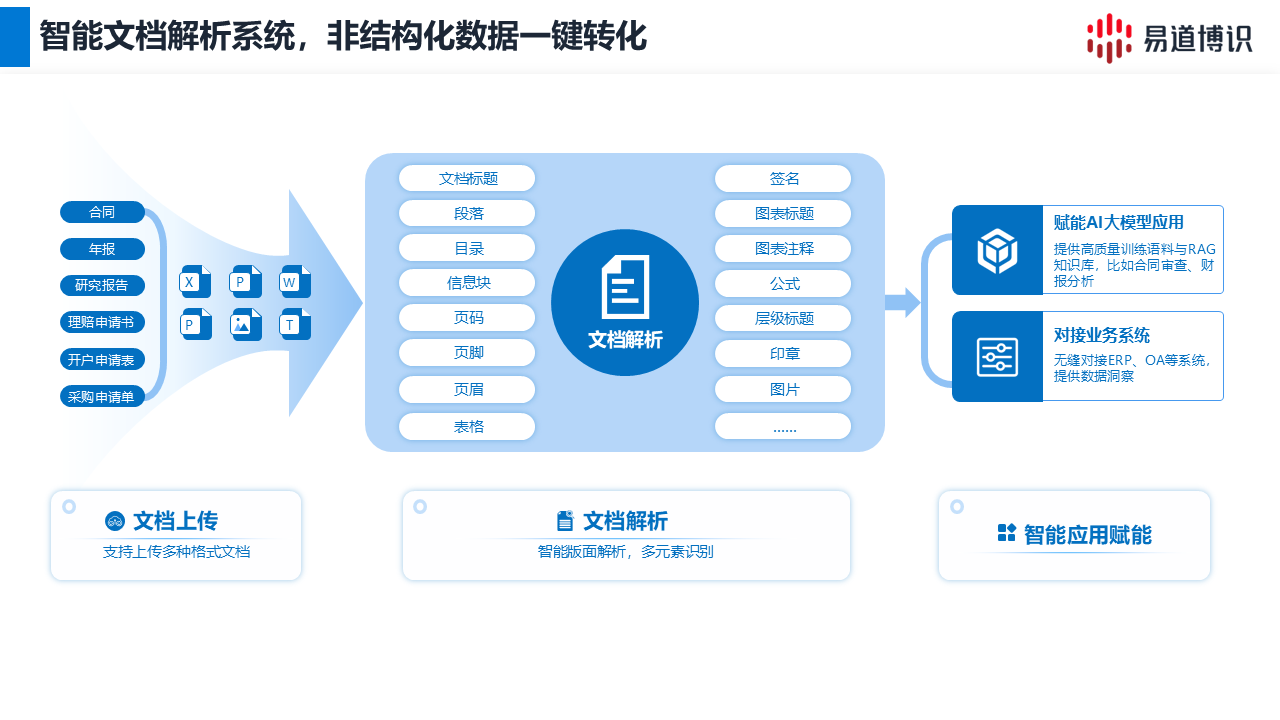
一個專業的系統能夠精準識別并結構化提取文檔中的所有核心元素,確保信息的完整性。
●基礎元素: 標題(包括多級標題)、段落、信息塊、頁眉、頁腳、頁碼。
●復雜元素: 表格(包括跨頁表格和嵌套復雜表格)、圖片、圖表標題、公式。
●特殊元素: 印章、手寫簽名。
易道博識智能文檔解析系統能夠智能識別多欄布局的邊界,并按照正確的閱讀順序(例如,先左欄后右欄)進行解析,確保文本的連續性。對于圖文混排,它會先區分出文本區域和圖片區域,再按照原始的圍繞關系或上下文順序進行重組。
例如,在解析學術論文時,傳統工具常將左右兩欄的文字混在一起。而易道博識智能文檔解析系統會先完整解析完第一欄,再接著解析第二欄,最終輸出的文本完全符合人類的閱讀邏輯。
可以。這是衡量一個文檔解析系統專業度的關鍵指標。
財務報表和大型數據清單中的表格經常會跨越多頁。專業的系統具備自動檢測并拼接跨頁表格的功能,它能識別出不同頁面上的表格片段屬于同一個邏輯表格,并將其無縫還原為一個完整、統一的數據表,極大地簡化了數據整合工作。
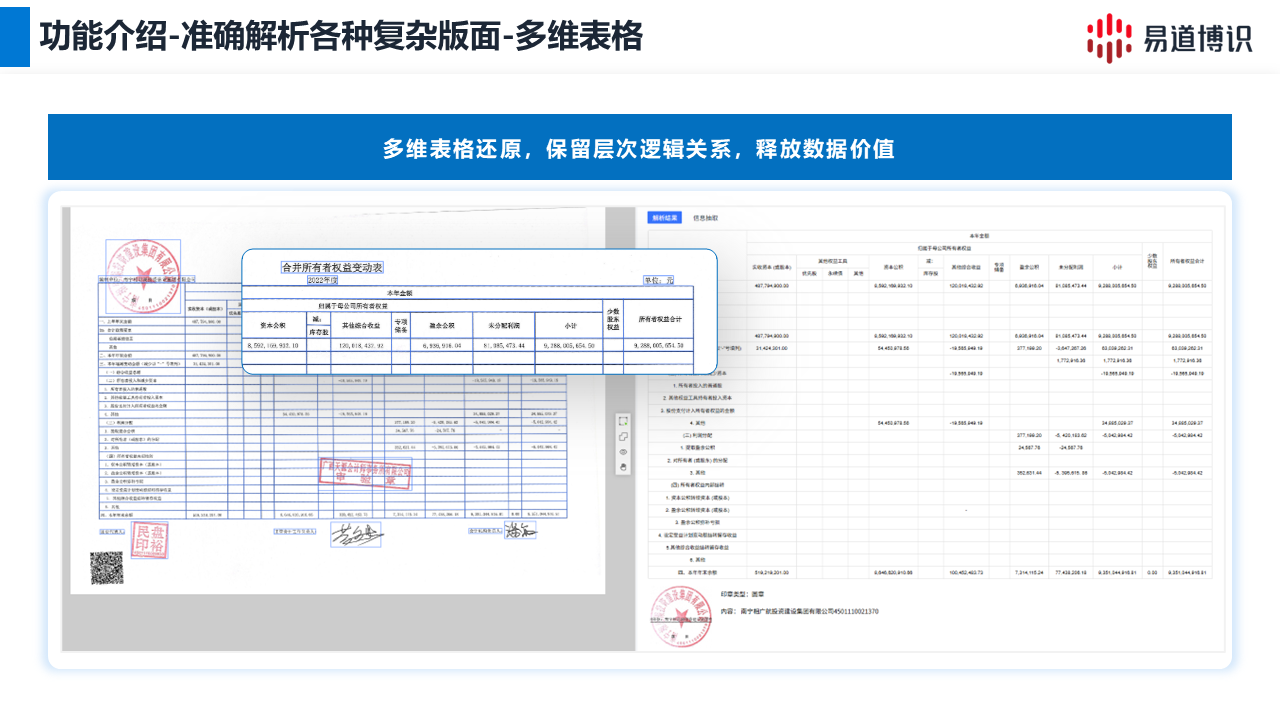
針對財報中常見的多級表頭、嵌套單元格等“多維表格”,易道博識智能文檔解析系統能夠深入解析其復雜的層級與隸屬關系。它不僅是提取數據,更是完整保留了數據之間的層次邏輯,將復雜的表格轉化為機器可讀的結構化數據(如JSON),真正釋放了深藏于表格中的數據價值。
為了無縫對接各類下游應用,系統通常提供多樣化的數據輸出格式。
1.Markdown: 這種格式能最大程度地保留原始文檔的版式和內容結構,如標題層級、列表、加粗等,非常適合用于構建知識庫。
2.JSON: 這種格式包含了每個文字、段落乃至表格單元格的精確坐標位置信息和置信度得分。它不僅支持數據可視化,還能對低置信度字符進行警示,便于人工高效校驗,是進行深度數據分析和應用集成的首選。