
EN
我們經常聽到客戶問如下問題:原生開源大模型就能OCR識別,為什么要采購易道博識二次訓練的OCR大模型,價值在哪?
事實上,在未經調優的情況下,直接將原生大模型用于OCR識別,很難滿足生產要求。
大模型OCR的技術路徑與固有局限
大模型實現OCR功能主要通過兩種技術路徑,兩者在架構上決定了其在實際應用中的固有局限。
多模態大模型:多模態大模型是“圖像輸入→文本輸出” 的端到端解決方案。模型通過統一的架構直接理解圖像中的視覺特征(如文字、布局)和語義信息,一步完成識別與信息提取。
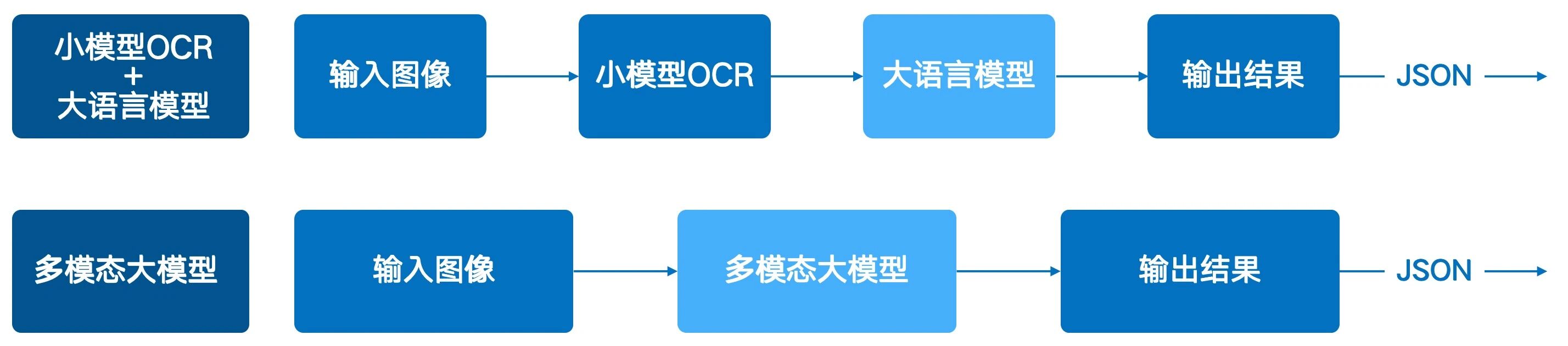
當原生大模型在應用于專業的OCR任務時,暴露出以下局限:
1、識別準確率不足
● 字符識別:在手寫體、印刷質量不佳或存在生僻字的情況下,識別錯誤率較高。
● 表格識別:對于包含合并單元格或復雜排版的表格,結構識別和內容提取的準確率會大幅下降。
● 數據提取:當文檔中缺少明確的關鍵字作為定位錨點時,模型提取特定字段的準確性顯著降低。
● 版式兼容性:在企業的財務流程中,發票、銀行回單、結算憑證等套打文檔無處不在,然而,一旦打印過程出現物理偏移,例如,發票上的關鍵字段“金額”或“收款人”未能精確打印在預設的表格框線內,模型便難以識別。

2、存在幻覺
“幻覺”是指模型生成了與圖像實際內容不符但看似合理的結果。
● 語義覆蓋內容:當圖像文字模糊時,模型可能依據上下文“腦補”出錯誤但符合邏輯的內容。例如,將模糊的金額“198”識別為更常見的“199”。
● 無中生有:對于圖像中本應為空白的字段,模型可能會強制生成內容。
● 長文本連貫性幻覺:對于長段落文本(如書籍掃描頁),大模型為保證輸出文本的連貫性,可能對個別識別模糊的詞進行 “合理化修正”,導致局部文本與原圖不符。
3、識別結果無法溯源
原生大模型在識別文本后,通常不提供其在原始圖像中的具體坐標位置,導致識別結果無法溯源。
這一局限在實際應用中會帶來兩類關鍵問題:
操作層面,當識別結果出錯時,用戶無法快速定位原文進行人工校對;
合規層面,尤其在金融、醫療等監管嚴格的領域,審計要求OCR結果必須與原始憑證的原文精確對應,因此,缺乏坐標溯源能力的技術無法滿足其合規標準。
4、精度與成本難平衡
模型精度與其參數規模正相關。千億級參數的大模型能達到更高的識別精度,但其推理計算必須依賴A100/H100級別的高端GPU,這使得硬件部署成本十分高昂。
反之,如果為了控制成本而采用參數裁剪或量化壓縮后的輕量化模型,會導致跨模態注意力機制、視覺特征編碼能力受損,OCR 精度大幅下降。例如,某多模態模型的 7B 參數版本在表格識別任務中的準確率比 130B 版本低 20% 以上。
為克服原生大模型的局限,易道博識采用“選擇模型與評測短板 - 定向訓練 - 驗證效果”的閉環流程,對基礎大模型進行二次訓練與調優。
1. 選擇與評測基礎模型: 首先,根據任務需求(如場景、語言、精度要求)選擇一個基礎大模型。在調優前,對其OCR能力進行全面評測,包括在印刷體、手寫體、不同噪聲背景下的文本識別準確率,以及表格識別和上下文理解能力,從而定位其具體短板,為后續訓練數據的篩選和調優策略(如重點強化手寫體數據的訓練)提供指導。
2. 定向數據訓練: 基于評測結果,構建針對性的訓練數據集。簡單來說,大模型在哪方面能力偏差,就要相應的增加相關訓練數據。
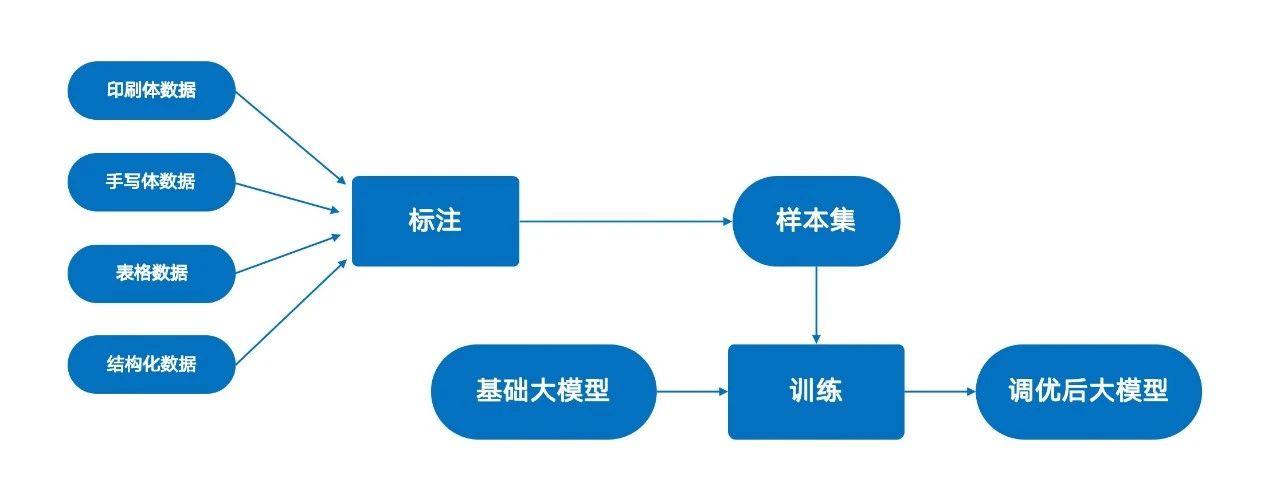
例如,若模型對手寫體識別能力較弱,則在訓練數據中增加手寫樣本的比例。我們使用海量經過專業標注的OCR數據,覆蓋印刷體、手寫體、各類表格及結構化文檔,對基礎大模型進行二次訓練,以增強其在特定任務上的特征學習能力。
3. 評估與驗證: 訓練完成后,在獨立的測試集上對調優后模型的各項性能指標進行重新評估,以驗證其相較于原生模型的提升,最終實現高精度、高魯棒性的 OCR 應用。
通過二次訓練,模型在準確率、速度和功能完備性上均獲得了顯著提升。最為重要的是,基于相對輕量化的大模型,經過二次訓練,其OCR綜合能力要遠好于更大參數規模的原生大模型,
丨準確率:30億參數模型優于720億參數模型
評測結果顯示,一個30億參數的多模態大模型經過二次訓練后,其在多種真實業務票據上的端到端識別準確率,不僅高于70億參數的原生模型,甚至全面優于720億參數的原生模型。
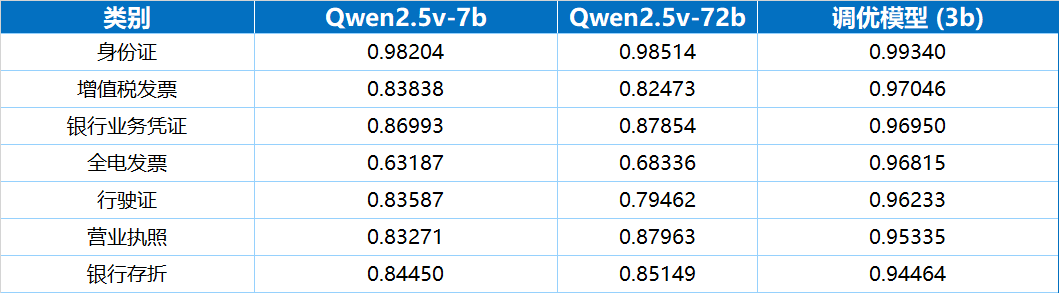
在相同的A100(80G)硬件環境下,處理同等復雜度的增值稅發票,720億參數的Qwen模型平均耗時21.43秒,而調優后的30億參數模型僅需3.23秒,處理速度為前者的6.63倍。
此外,通過并行任務設計和工程上的優化,進一步加速了大模型推理:在信息抽取任務上,將實體抽取、表格抽取任務拆開并行計算,理論速度可再提升最高100%。
與原生大模型不同,經過二次訓練的模型支持輸出每個識別字段在原始圖像中的精確坐標。這一功能解決了結果無法溯源的問題,滿足了業務核驗與合規審計的需求。
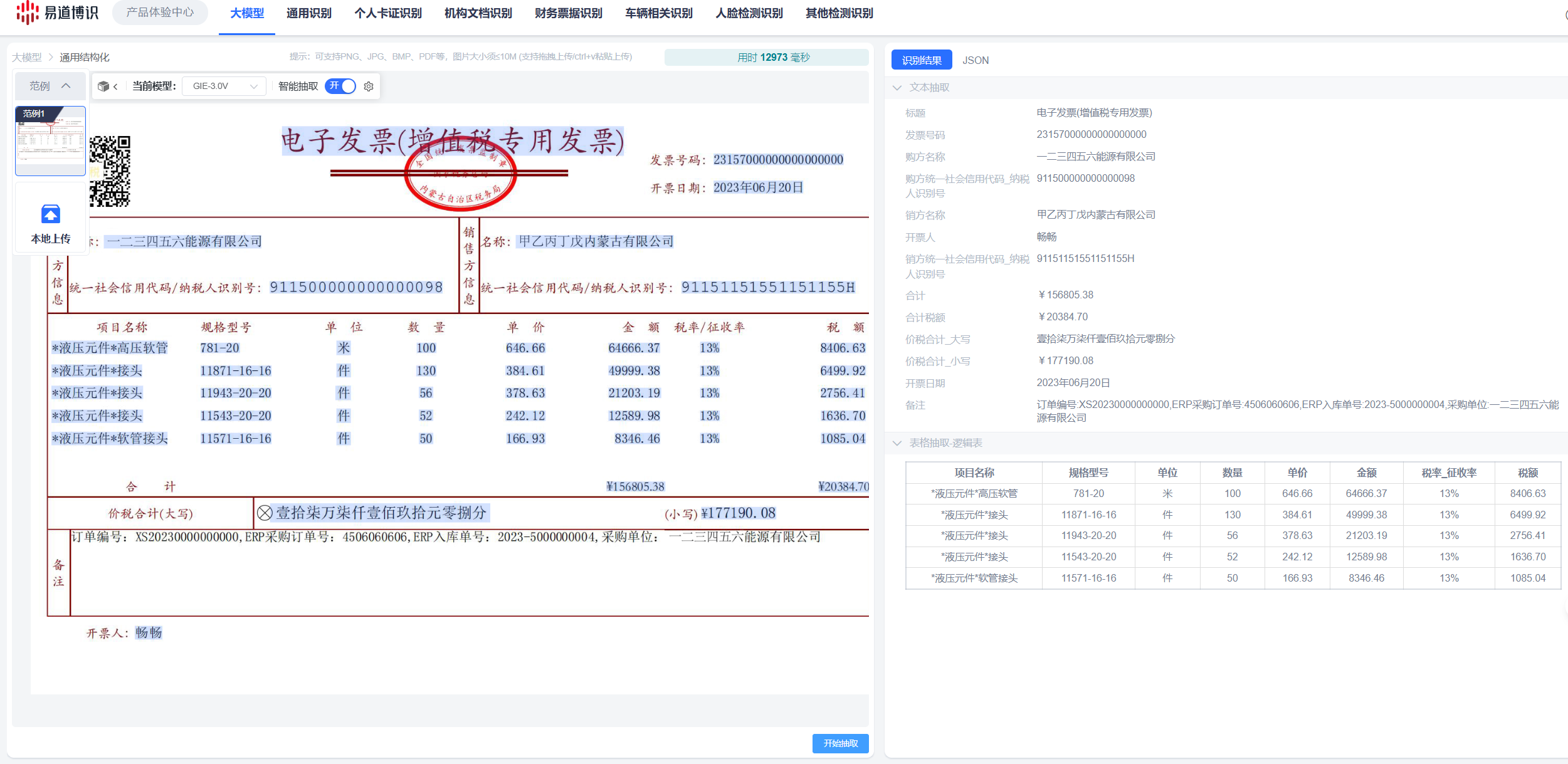
為降低大模型在業務系統中的使用門檻,我們進行了兩項關鍵的工程化改造。
大模型與普通 OCR 接口在輸入輸出邏輯上存在顯著差異:
傳統 OCR 接口采用 "圖像→結構化數據" 的固定模式,通常僅接收圖像輸入,輸出包含文字內容及位置信息的 JSON 格式數據。
原生大模型采用“圖像+提示詞”的協同輸入模式,其優勢在于能進行深度語義理解,實現更精準的信息提取。
然而,這一模式也帶來了兩個問題:一是要求用戶具備為不同文檔設計提示詞的能力,二是其流式輸出與標準的JSON格式不兼容,這都顯著增加了非專業用戶的使用門檻。
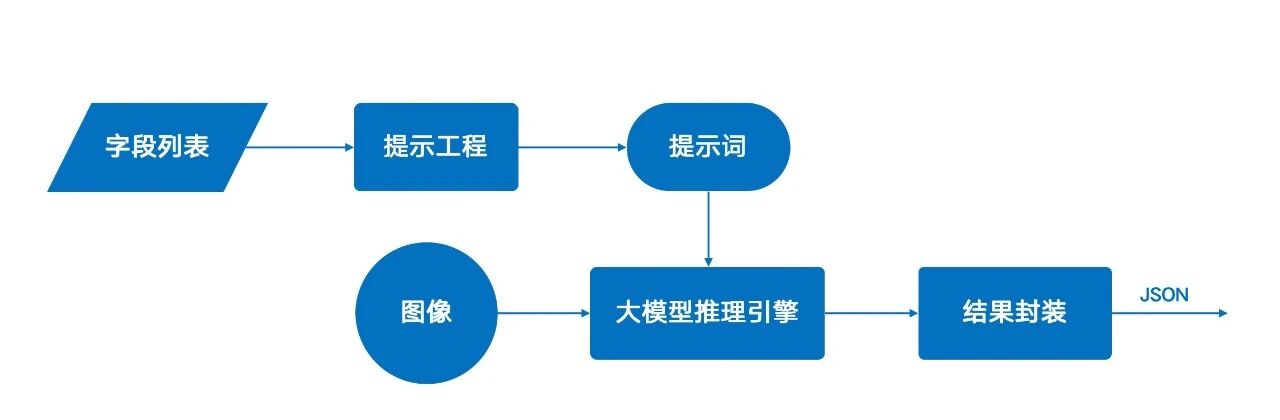
為此,易道博識通過工程化手段,將復雜的調用邏輯封裝成標準API。用戶只需提供圖像和待提取的字段列表,系統即可自動構建提示詞并返回結構化的JSON結果,其使用體驗與傳統OCR接口一致。
由于用戶無需自行定義復雜的提示詞,也無需處理復雜的和大模型的交互過程,因而接口更加方便易用。
從當前技術實踐來看,大模型更多是對小模型的有益補充,而非全然替代。二者的深度融合,才是現階段應對復雜場景的最優解。
需要注意的是,原生狀態下的大模型與小模型往往難以實現深度協同 。傳統解決方案多采用獨立部署模式,在應用層根據具體需求分別調用大模型或小模型的接口,這種方式難以突破 “各自為戰” 的局限。
而易道博識通過系統化的工程化手段,成功實現了大小模型的深度融合,智能文檔處理平臺(簡稱DeepIDP)架構如下:

DeepIDP在底層集成了小模型推理引擎和大型模型推理引擎。該架構可以根據任務的復雜度和需求,自動調度最合適的模型進行處理,對外提供標準化的服務接口。
這種融合架構屏蔽了底層模型的差異,實現了“無感調用”,用戶無需刻意區分某個識別能力是由大模型還是小模型提供,只需專注于自身業務需求即可。
在確保高性能和高效率的同時,簡化了系統維護,為業務創新提供了更靈活的底層AI能力支持。





