智能文字識別
智能文檔處理
智能圖像處理
自然語言處理
領域模型學習能力
銀行
證券
保險
行業
公司新聞
行業資訊
公司介紹
發展歷程
榮譽資質
服務體系
招聘信息
聯系方式
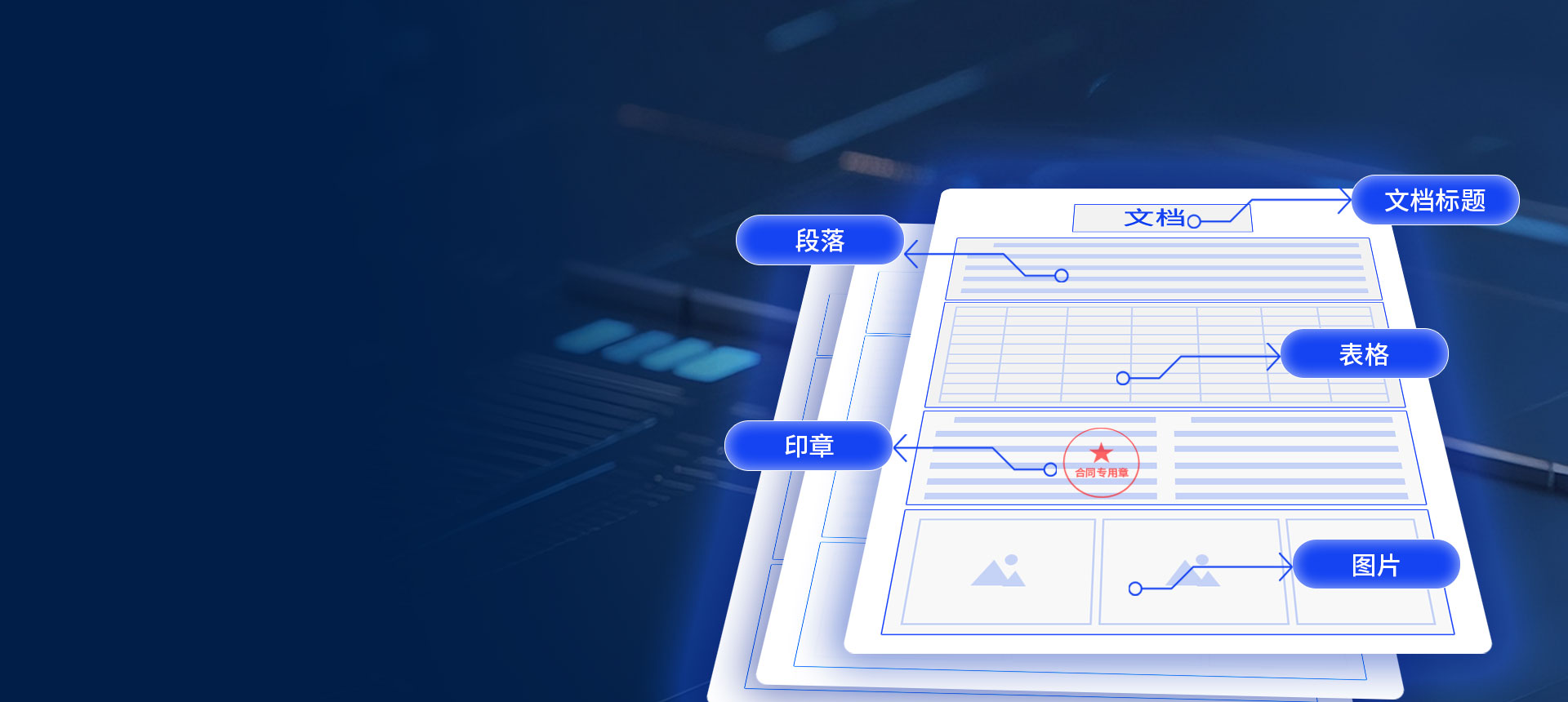
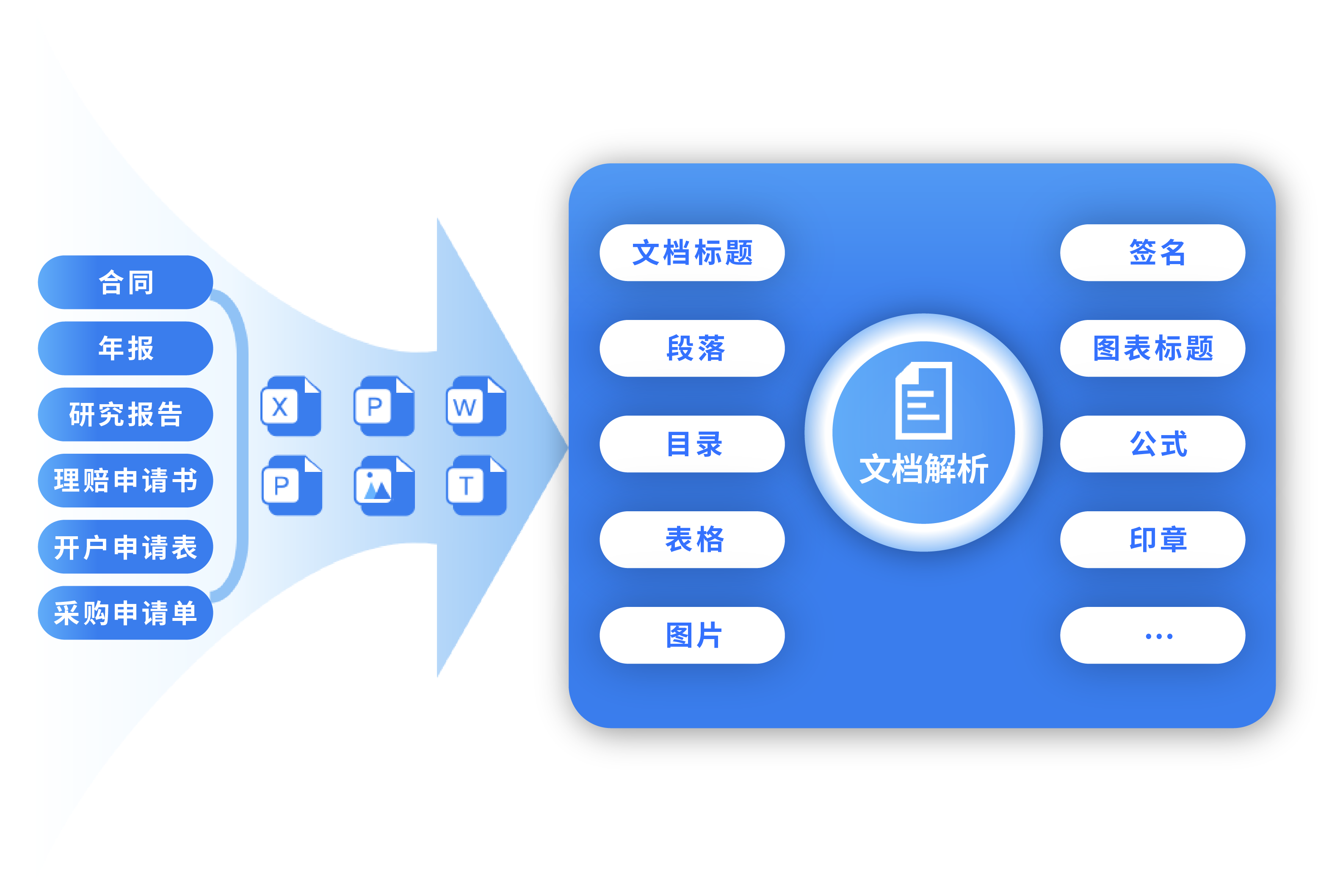
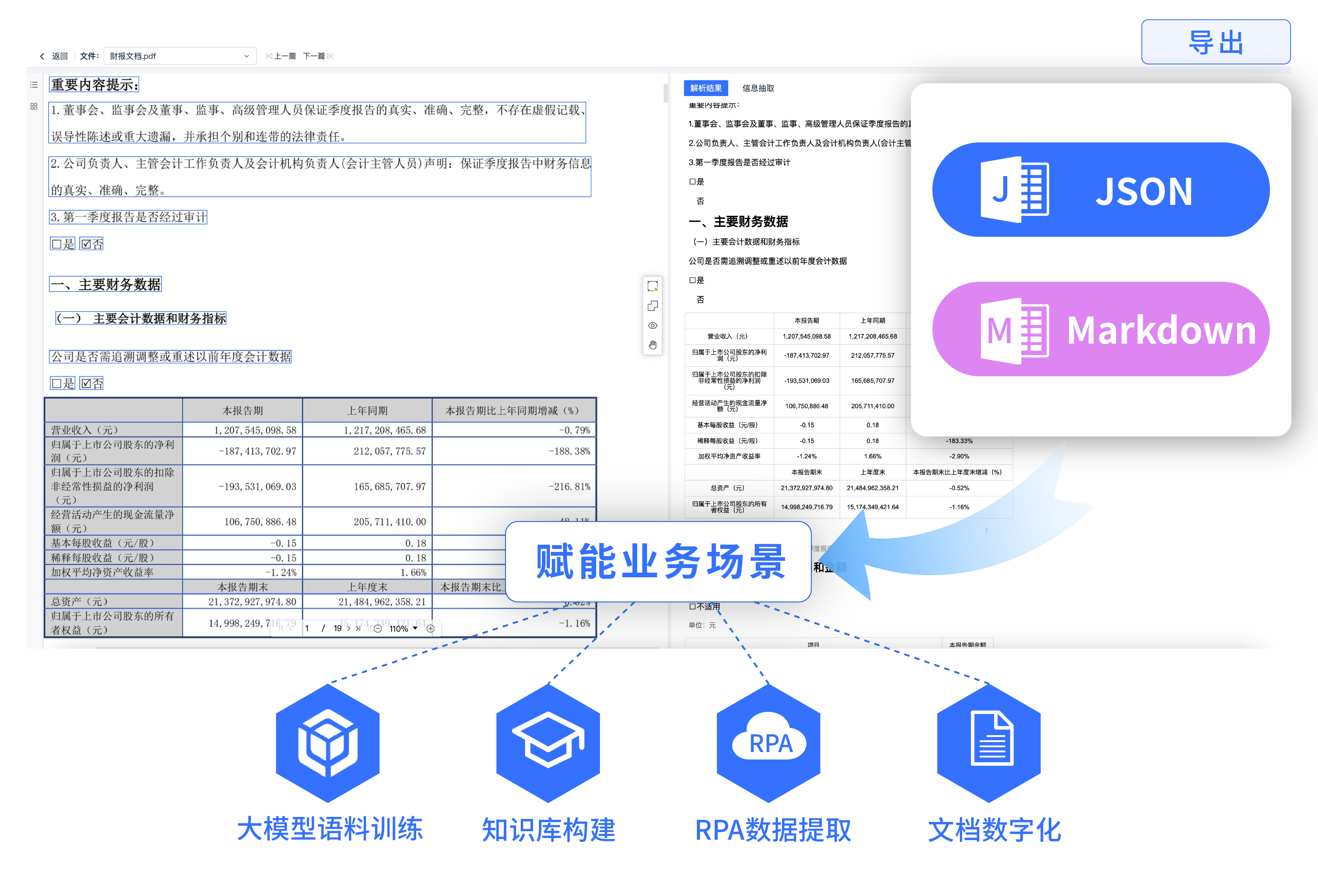
將合同、年報、研究報告、理賠申請書等復雜文檔轉換為可編輯、可檢索的結構化數據。精準解析并提取文檔中的各類元素,按閱讀順序還原版面,無縫集成至業務系統,提升文檔處理效率與數據利用率。
支持批量解析 PDF、JPG、PNG、Word等格式文檔。 精準識別并提取文檔中的各類版面元素,包括標題、段落、目錄、頁眉頁腳、表格、圖片、印章、公式等。
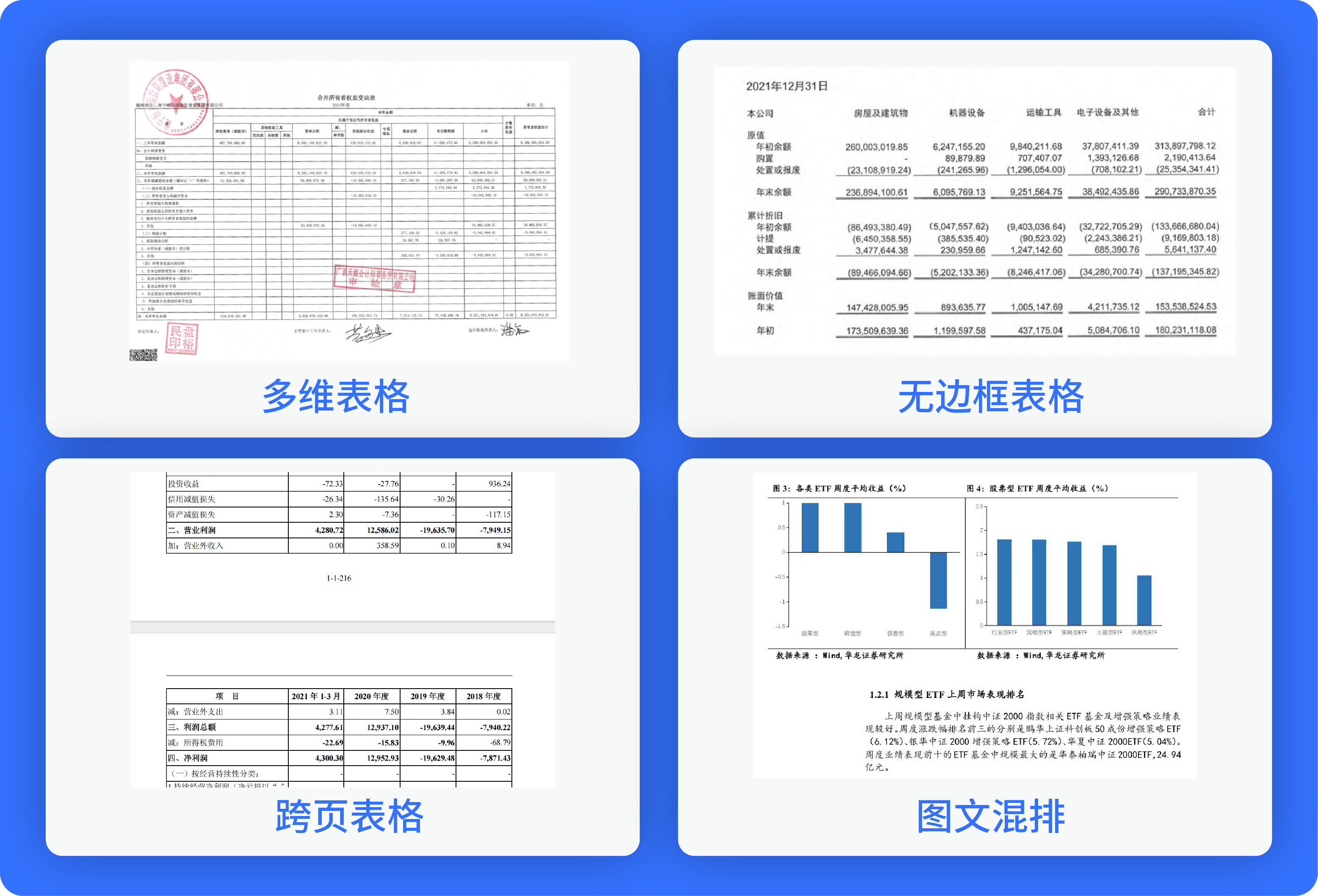
輕松解析各類復雜版式文檔,無論是圖文混排,還是跨頁、多維、無邊框等表格版式,均可按閱讀順序還原。
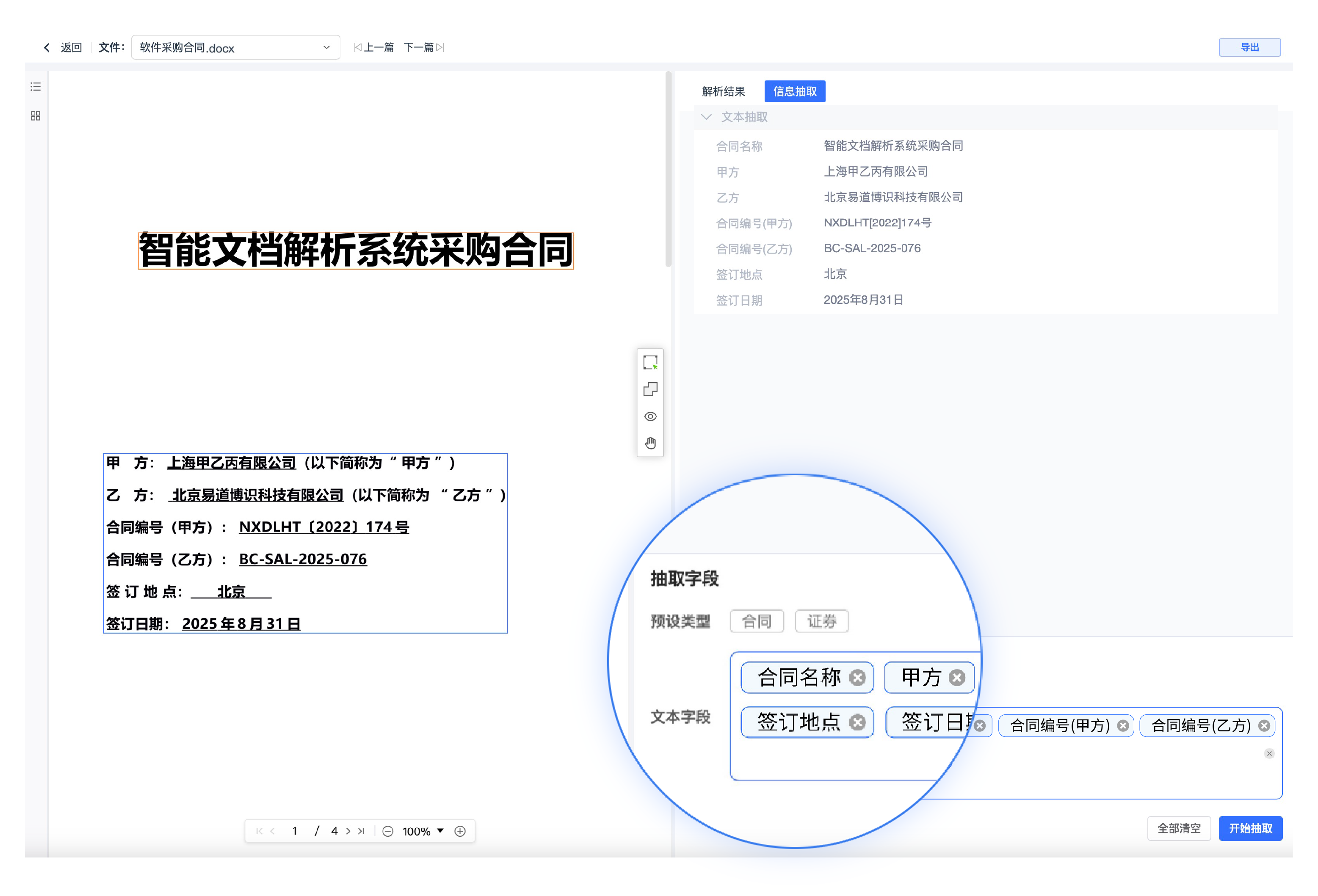
系統內預設模板,并自持自定義抽取,僅需輸入提示詞即可實現任意版式文檔字段抽取。
支持輸出Markdown和JSON格式,保留原始文檔的版式與內容。 支持大模型語料訓練、知識庫構建、RPA數據提取、文檔數字化等業務場景。
從文檔輸入、識別解析到結構化輸出端到端處理,賦能多元業務場景。
精準解析多格式、多類型文檔,尤其擅長處理金融領域常見的異形表格與復雜排版。
支持大批量文檔解析,保障225頁/分鐘 的吞吐量,而且支持企業靈活擴容。
全面適配信創生態,支持全棧國產化部署,滿足企業數據安全與自主可控要求。
微信小程序
易識APP
掃一掃,關注我們