
EN

“垃圾進(jìn),垃圾出”是AI領(lǐng)域的第一定律。AI應(yīng)用的智能上限,直接由其學(xué)習(xí)的數(shù)據(jù)質(zhì)量決定。對(duì)于依賴(lài)企業(yè)內(nèi)部文檔(如PDF、報(bào)告、手冊(cè))的AI系統(tǒng),低質(zhì)量數(shù)據(jù)是致命的。
然而,企業(yè)的大部分文檔在解析時(shí),經(jīng)常會(huì)標(biāo)題層級(jí)錯(cuò)亂,表格被拆分變形,多欄格式無(wú)法識(shí)別。導(dǎo)致無(wú)法形成完成的語(yǔ)義,數(shù)據(jù)得不到有效利用。
將原始、混亂的非結(jié)構(gòu)化文檔,轉(zhuǎn)化為AI能高效利用的“數(shù)據(jù)養(yǎng)料”,需要一個(gè)系統(tǒng)性的“數(shù)據(jù)精煉廠”。
第一步:如何為模型預(yù)訓(xùn)練構(gòu)建高質(zhì)量語(yǔ)料?
此階段的目標(biāo)是“清洗與結(jié)構(gòu)化”。一個(gè)強(qiáng)大的系統(tǒng)需要具備以下能力:
●智能版面分析:精準(zhǔn)處理圖文混排、多欄布局等復(fù)雜版式,確保文本按正確的閱讀順序被提取。
●關(guān)鍵元素識(shí)別:準(zhǔn)確識(shí)別并標(biāo)記標(biāo)題、段落、列表、表格等不同元素。
●表格結(jié)構(gòu)化重組:對(duì)于跨越多頁(yè)的復(fù)雜表格,能自動(dòng)完成拼接,將其還原為一個(gè)完整的、可供分析的數(shù)據(jù)單元。
處理后的產(chǎn)出是完全遵循原文邏輯、結(jié)構(gòu)清晰的語(yǔ)料庫(kù),能從源頭上保障模型訓(xùn)練的質(zhì)量。
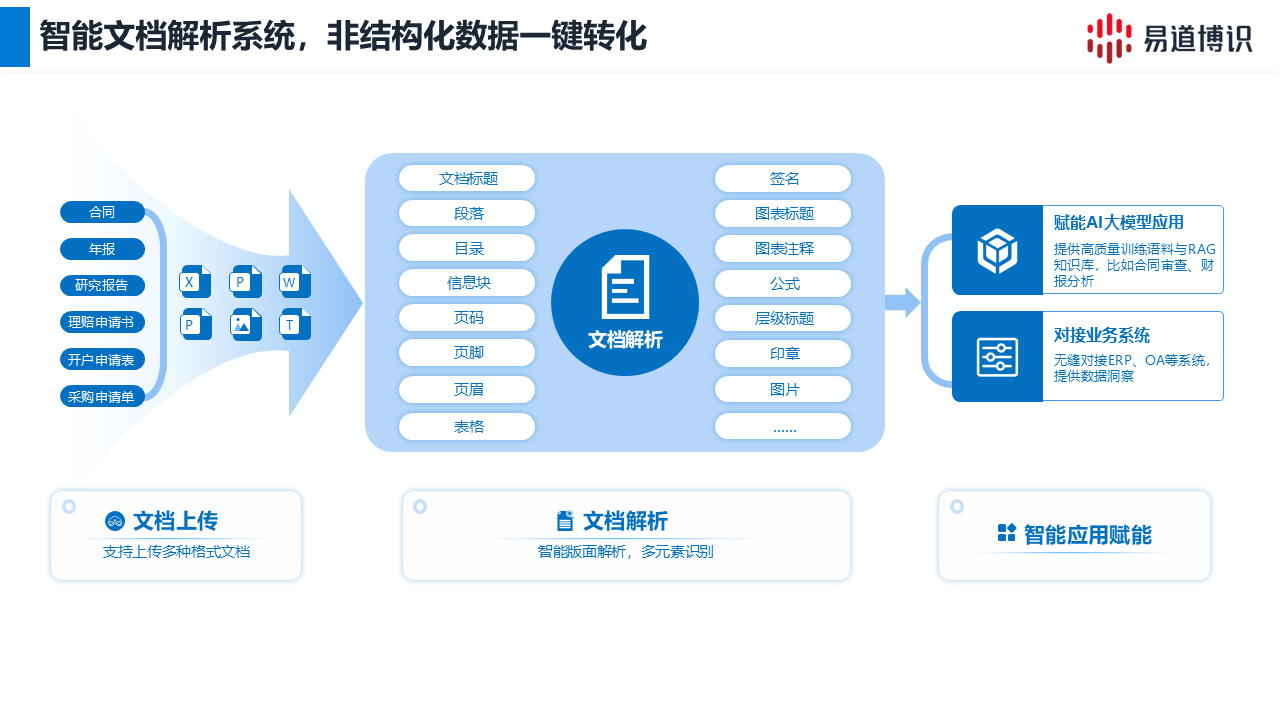
第二步:如何為RAG應(yīng)用構(gòu)建更高質(zhì)量的知識(shí)庫(kù)?
RAG(檢索增強(qiáng)生成)應(yīng)用成功的關(guān)鍵在于檢索的精準(zhǔn)度。這依賴(lài)于知識(shí)庫(kù)的構(gòu)建方式,核心技術(shù)是“邏輯分塊(Logical Chunking)”。
●傳統(tǒng)方式(固定長(zhǎng)度分塊):強(qiáng)行按字?jǐn)?shù)(如512個(gè)字符)切分文檔。這種方法極易將一個(gè)完整的段落或表格從中間切斷,破壞語(yǔ)義完整性。
●邏輯分塊(推薦方式):以段落、表格、或一個(gè)完整的“標(biāo)題-正文”組合等具備內(nèi)在邏輯的語(yǔ)義單元作為邊界進(jìn)行分塊。
例如,當(dāng)用戶(hù)提問(wèn)時(shí),邏輯分塊能確保系統(tǒng)召回的是一個(gè)語(yǔ)義完整、自包含的知識(shí)單元(比如一整個(gè)完整的表格),從而為大模型提供最充分的判斷依據(jù),這是從根本上減少內(nèi)容幻覺(jué)、提升答案準(zhǔn)確性的最有效途徑。
易道博識(shí)智能文檔解析系統(tǒng),專(zhuān)注于精準(zhǔn)還原復(fù)雜文檔的版面結(jié)構(gòu)。
1.全面的格式支持與元素識(shí)別:支持PDF、圖片等多種格式,可全面識(shí)別標(biāo)題、段落、表格等元素,實(shí)現(xiàn)內(nèi)容結(jié)構(gòu)化。
2.復(fù)雜版式版面還原:系統(tǒng)能確保圖文混排和多欄布局的正確閱讀順序,避免語(yǔ)義混淆;可自動(dòng)拼接跨頁(yè)表格,并深度解析含多級(jí)表頭、嵌套單元格的復(fù)雜表格,完整保留其數(shù)據(jù)邏輯;同時(shí)還能重建文檔的標(biāo)題層級(jí),構(gòu)建清晰的邏輯骨架。最終,系統(tǒng)能夠輸出與原始版面在內(nèi)容和結(jié)構(gòu)上高度一致的結(jié)構(gòu)化數(shù)據(jù)。
3. 智能抽取與多樣化格式輸出:用戶(hù)可以選擇輸出Markdown格式,以最大程度地保留原始文檔的版式和內(nèi)容結(jié)構(gòu);也可以選擇輸出JSON格式,該格式包含了每個(gè)文字、字塊乃至段落的精確坐標(biāo)位置信息和置信度得分,不僅支持后續(xù)的數(shù)據(jù)可視化與交互式修改,還能對(duì)低置信度字符提供警示,便于人工高效校驗(yàn)。

1.智能文檔解析系統(tǒng)支持圖片格式的文檔嗎?
答: 支持。系統(tǒng)能夠處理通過(guò)掃描或拍照生成的文檔圖片,如JPG、PNG格式,并同樣進(jìn)行高精度的版面解析與結(jié)構(gòu)化處理。
2.文檔解析和普通的OCR識(shí)別有什么區(qū)別?
答: 本質(zhì)區(qū)別在于“理解”。普通OCR軟件的目標(biāo)是“識(shí)別文字”,而智能文檔解析系統(tǒng)的目標(biāo)是“理解文檔”。它不僅識(shí)別文字,更重要的是理解文字的角色(是標(biāo)題還是正文)、元素間的關(guān)系(如圖文對(duì)應(yīng)、表格結(jié)構(gòu))以及正確的閱讀順序。




